



Recent post
Archive for mayo 2017
Las siguientes instrucciones pertenecen al DML y como ya vimos, hacen uso de los datos almacenados en la base de datos:
SELECT
La instrucción SELECT es aquella que nos va a mostrar las columnas deseadas en la relación derivada. Su forma mas simple es la siguiente:
SELECT columnas FROM tablas_referencia
INSERT
La instrucción INSERT nos sirve para agregar tuplas en una tabla
INSERT INTO nombre_tabla (columna1, columna2, ...) VALUES (valor1, vlor2, ...);
UPDATE
La instrucción UPDATE modifica los valores de los campos y registros especificados
UPDATE nombre_tabla SET columna1 = valor1, columna2 = valor2, ... WHERE condicion
DELETE
La instrucción DELETE elimina registros de una tabla especifica
DELETE FROM nombre_tabla WHERE condicion
Estas instrucciones pueden ser potenciadas con ciertas clausulas las cuales son condiciones que modifican el resultado de la relación derivada. Dentro de estas encontramos las siguientes:
FROM: Nos sirve para seleccionar las tablas de las cuales vamos a extraer la información deseada.
Por ejemplo: SELECT * FROM tablas(s)
WHERE: Nos sirve para seleccionar las filasde las cuales vamos a extraer la información que cumpla cierta condicion.
Por ejemplo: SELECT * FROM tablas(s) WHERE condicion
GROUP BY: Nos sirve para separar los registros seleccionados en grupos específicos
Por ejemplo: SELECT * FROM tablas(s) WHERE condicion GROUP BY columna
HAVING: Nos sirve para expresar la condición que debe satisfacer cada grupo
Por ejemplo: SELECT * FROM tablas(s) WHERE condicion GROUP BY columna HAVING condicion
GROUP BY: Nos sirve para ordenar los registros seleccionados de acuerdo con un orden específico
Por ejemplo: SELECT * FROM tablas(s) WHERE condicion ORDER BY ASC/DESC
Si no se especifica el order by se ordenara de forma ascendente de manera automática
Dentro de las condiciones podemos usar distintos operdores para encontrar los datos deseados. Entre estos tenemos:
- < (menor que)
- > (mayor que)
- <> (diferente de)
- <= (menor igual que)
- >= (mayor igual que)
- = (igual que)
- BETWEEN (devuelve valores en un rango definido)
SELECT * FROM tabla WHERE columna BETWEEN num1 AND num2 - LIKE (usado para la comparación)
SELECT * FROM tabla WHERE columna LIKE a% (devuelve valores que inician con a) - IN (usado para especificar registros)
SELECT * FROM tabla WHERE columna IN (num1,num2,...)
Estas van despues del WHERE y pueden ponerse mas de una con el uso de AND (y), OR (o) y NOT (valor contrario al especificado)
El DDL tiene tres instrucciones básicas las cuales veremos con profundidad a continuación:
CREATE Crea un objeto de un determinado tipo (DATABASE, TABLE, INDEX, etc.) con un nombre (por ejemplo Inventarios, Libros, Autores, etc.) y una definición (CodigoA, Nombre, etc.).
La estructura de esta instrucción es la siguiente:
CREATE tipo nombre definición
DROP elimina un tipo de objeto especificado mediante un nombre, su estructura es la siguiente:
DROP tipo nombre
ALTER Modifica la definición de un objeto. Un ejemplo de su uso seria
ALTER TABLE Autores DROP COLUMN nacionalidad
CREATE Crea un objeto de un determinado tipo (DATABASE, TABLE, INDEX, etc.) con un nombre (por ejemplo Inventarios, Libros, Autores, etc.) y una definición (CodigoA, Nombre, etc.).
La estructura de esta instrucción es la siguiente:
CREATE tipo nombre definición
DROP elimina un tipo de objeto especificado mediante un nombre, su estructura es la siguiente:
DROP tipo nombre
ALTER Modifica la definición de un objeto. Un ejemplo de su uso seria
ALTER TABLE Autores DROP COLUMN nacionalidad
En informática, cuando se quiere hacer uso de un lenguaje de programación se requiere de una sintaxis para escribir de forma correcta cada una de las instrucciones. Para escribirlas adecuadamente se debe respetar ciertas reglas en cuanto a la forma en la cual deben de escribirse, en este caso, instrucciones que el compilador o interprete de comando sea capaz de "entender" y hacer lo que nosotros estamos indicando.
Algo muy importante es, que el sistema hará justo lo que nosotros le indiquemos, si la instrucción es incorrecta entregara resultado no esperados o simplemente no hará nada.
SQL es un lenguaje de consulta estructurado, este a su vez esta subdividido en dos tipos diferentes de lenguaje:
DDL (Lenguaje de definición de datos): Este lenguaje es el encargado de la creación, eliminación y modificación de las estructuras donde se almacenaran los datos. Estas son las tablas, bases de datos, vistas, etc.
DML (Lenguaje de manipulación de datos): Contiene las funciones que se encargaran mostraran, eliminaran, actualizaran e insertaran la información dentro de nuestra base.
Dependiendo de que realice la instrucción entrara dentro de estas 2 clasificaciones. Para hacer uso de estas se necesita tener instalado un SGBD y de preferencia una interfaz para hacer el trabajo mas sencillo.
Una vez instalado y ya con la base de datos creada podemos proceder a realizar consultas para su correcto funcionamiento.
Las operaciones básicas del álgebra relacional se han extendido o ampliado de varias maneras.
Esta función amplía la proyección permitiendo que se utilicen funciones aritméticas en la lista de proyección.
Este tipo de operaciones se pueden como su nombre lo dice agregar a la operación de proyección, dichas operaciones toman un conjunto de valores y retornan o proyectan un valor ÚNICO. Las operaciones son:
- Una de las extensiones es permitir operaciones aritméticas como parte de la operación proyección (Proyección Generalizada).
- Permitir operaciones de agregación.
PROYECCIÓN GENERALIZADA
Esta función amplía la proyección permitiendo que se utilicen funciones aritméticas en la lista de proyección.
FUNCIONES DE AGREGACIÓN
Este tipo de operaciones se pueden como su nombre lo dice agregar a la operación de proyección, dichas operaciones toman un conjunto de valores y retornan o proyectan un valor ÚNICO. Las operaciones son:
- SUM: retorna la suma de los valores
- AVG: retorna la media de los valores
- MIN: retorna el mínimo de los valores
- MAX: retorna el máximo de los valores
- COUNT: retorna el número de elementos del conjunto
Join
El JOIN Natural es una operación binaria que permite combinar ciertas selecciones y un producto cartesiano en una sola operación. Se denota por el símbolo: ⋈
R ⋈θ S

Permite usar cualquier condición de comparación. Es equivalente a: σ θ (R X S)
Θ - Join
R ⋈θ S
Equivalente al Join solo que se permite usar cualquier condición de comparación. θ.
El resultado se construye:
- Toma el R X S
- Selecciona solo las tuplas que satisfacen a θ.
- es equivalente a: σ θ (R X S)

En álgebra relacional el producto de dos relaciones A y B
es:
A Veces B o A X B
Produce el conjunto de todas las tuplas t tales que t es el
encadenamiento de una tupla a perteneciente a A y de una b que pertenece a B.
se utiliza el símbolo X para representar el producto.
Esta operación es importante para encontrar los valores de 2 o mas relaciones las cuales están relacionadas entre ellas.
En álgebra relacional la diferencia entre dos relaciones compatibles A y B es igual a
A MENOS B o A – B
Esta operación produce el conjunto de todas las tuplas t que pertenecen a A y no pertenecen a B.
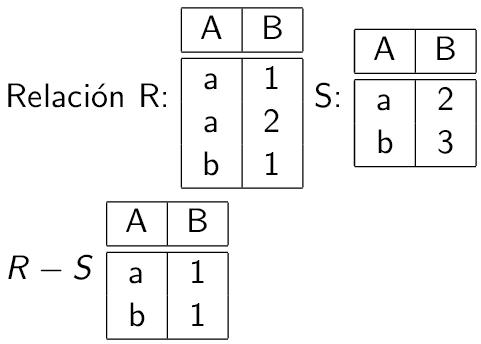
el siguiente vídeo nos dará una explicación sobre la diferencia en el álgebra relacional
En álgebra relacional la unión de dos relaciones compatibles
A y B es:
A UNION B o A U B
Produce el conjunto de todas las tuplas que pertenecen ya
sea a A o a B o a Ambas. Al igual que en teoría de conjuntos el símbolo U representa aquí la unión de dos relaciones.
Al adaptar los operadores de conjuntos a relaciones se debe
asegurar que exista compatibilidad entre ellas.
- Tienen el mismo grado.
- Los atributos tienen el mismo nombre.
- El dominio del sus atributos debe ser el mismo

La operación de proyección permite quitar ciertos atributos
de la relación, esta operación es unaria, copiando su relación base dada como
argumento y quitando ciertas columnas, La proyección se señala con la letra
griega pi mayúscula. Como subíndice se coloca una lista de todos los atributos
que se desea aparezcan en el resultado. La relación argumento se escribe
después de la relación entre paréntesis.


El álgebra relacional consiste de algunas simples pero
poderosas maneras de construir nuevas relaciones a partir de otras. Si pensamos
que las relaciones iniciales son los datos almacenados entonces las nuevas
relaciones se pueden ver como respuestas a algunas consultas deseadas.
El álgebra relacional es un lenguaje de consulta procedural.
Consta de un conjunto de operaciones que toman como entrada una o dos
relaciones y producen como resultado una nueva relación, por lo tanto, es
posible unir y combinar operadores. Hay ocho operadores en el álgebra
relacional que construyen relaciones y manipulan datos, estos son:
1. Selección 2.
Proyección 3. Producto
4. Unión 5.
Intersección 6. Diferencia
7. JOIN 8. División
Conceptos previos
Al describir las propiedades de cada operador se van a
utilizar una serie de términos que debemos definir previamente. En primer lugar
se presentará una adaptación del concepto de relación matemática en la que se
vuelve a hacer uso de la ordenación de las componentes de una tupla. El resto,
son expresiones o reformulaciones de conceptos ya presentes en la definición
del modelo.
Los conceptos a definir son:
- Relación: El AR hace uso del orden de las componentes de las tuplas para definir operadores y propiedades de los operadores. En realidad, se trata de retomar la definición original de la relación matemática como el subconjunto de un producto cartesiano de n dominios, de tal forma que las tuplas resultado de ese producto cumplían y cumplen que las tuplas son listas de valores (conjunto ordenado) tal que el i-ésimo valor pertenece al i-ésimo dominio.
- Esquema de relación: Es la descripción formal de la relación con sus atributos y dominios asociados. En realidad se aplica únicamente a las relaciones nominadas, aquellas descritas en el esquema lógico relacional.
- Alias de una relación: Es el nombre alternativo que se le da a una relación.
- Relación nominada: Es toda relación definida en el esquema lógico relacional. En otras palabras, las que constituyen nuestra base de datos.
- Relación derivada: Es aquella que se obtiene como resultado de una expresión del Álgebra Relacional. Una relación derivada no tiene nombre ni alias. Así pues, los nombres de los atributos de ésta se obtendrán a partir de los nombres cualificados de atributos de las relaciones operando, y si existe ambigüedad se utilizarán los alias.
- Relaciones compatibles: Dos relaciones son compatibles si el grado de ambas es el mismo y los dominios asociados a los i-ésimos atributos de cada una son iguales. Dicho de otra forma, el número de atributos ha de ser el mismo en ambas relaciones y, además, los dominios han de ser los mismos para atributos de la misma posición.
Para ejecutar algunas operaciones se deben cumplir algunas
restricciones:
- En las operaciones de UNION, INTERSECCIÓN y DIFERENCIA las relaciones deben ser compatibles.
- En la CONCATENACIÓN o JOIN deben existir atributos comunes, de lo contrario el resultado será el producto cartesiano.
- Para la DIVISIÓN, se debe cumplir que existan atributos
comunes
* de no haberlos, el resultado es vacío de tuplas
* los únicos del divisor
* los últimos del dividendo
* en el mismo orden en dividendo y divisor
Existen formas normales FN4, FN5, FNDK, FN6 cuyo aplicación
en el mundo real es meramente teórica, ya que en modelos reales no son
aplicables y pueden generar mayores dificultades que beneficios.
A manera de conocimiento básico las formas normales 4 y 5 se
ocupan del análisis de las dependencias entre atributos multivaluados, la forma
normal FNDK (Forma Normal Dominio Clave) trata acerca de las restricciones y
los dominios de los atributos y por último la FN6 se refiere a las consideraciones
que se deben tratar o tomar en cuenta con las bases de datos temporales.


Conceptos básicos
La normalización es el proceso de organizar los datos de una
base de datos. Se incluye la creación de tablas y el establecimiento de
relaciones entre ellas según reglas diseñadas tanto para proteger los datos
como para hacer que la base de datos sea más flexible al eliminar la
redundancia y las dependencias incoherentes.
Los datos redundantes desperdician el espacio de disco y
crean problemas de mantenimiento. Si hay que cambiar datos que existen en más
de un lugar, se deben cambiar de la misma forma exactamente en todas sus
ubicaciones.
Dependencia incoherente
Aunque es intuitivo para un usuario mirar en la tabla
Clientes para buscar la dirección de un cliente en particular, puede no tener
sentido mirar allí el salario del empleado que llama a ese cliente. El salario
del empleado está relacionado con el empleado, o depende de él, y por lo tanto
se debería pasar a la tabla Empleados. Las dependencias incoherentes pueden
dificultar el acceso porque la ruta para encontrar los datos puede no estar o
estar interrumpida.
Hay algunas reglas en la normalización de una base de datos.
Cada regla se denomina una "forma normal". Si se cumple la primera
regla, se dice que la base de datos está en la "primera forma
normal". Si se cumplen las tres primeras reglas, la base de datos se
considera que está en la "tercera forma normal". Aunque son posibles
otros niveles de normalización, la tercera forma normal se considera el máximo
nivel necesario para la mayor parte de las aplicaciones.
Al igual que con otras muchas reglas y especificaciones
formales, en los escenarios reales no siempre se cumplen los estándares de
forma perfecta. En general, la normalización requiere tablas adicionales y
algunos clientes consideran éste un trabajo considerable. Si decide infringir
una de las tres primeras reglas de la normalización, asegúrese de que su
aplicación se anticipa a los problemas que puedan aparecer, como la existencia
de datos redundantes y de dependencias incoherentes. (Support Microsoft, 2016)
Uno de los parámetros que mide la calidad de una base de
datos es la forma normal en la que se encuentra su diseño. Esta forma normal puede
alcanzarse cumpliendo ciertas restricciones que impone cada forma normal al
conjunto de atributos de un diseño. El proceso de obligar a los atributos de un
diseño a cumplir ciertas formas normales se llama NORMALIZACIÓN.
Las formas normales pretenden alcanzar dos objetivos:
- Almacenar en la base de datos cada hecho solo una vez, es decir, evitar la redundancia de datos. De esta manera se reduce el espacio de almacenamiento.
- Que los hechos distintos se almacenen en sitios distintos. Esto evita ciertas anomalías a la hora de operar con los datos.
Las restricciones en una base de datos se refieren a las condiciones que deben cumplir los datos para su correcto funcionamiento y almacenamiento. Existen varios tipos.
- Restricciones de clave: Es el conjunto de atributos que identifican de forma única a una entidad:
- Restricciones de valor único (UNIQUE): Es una restricción que impide que tenga un atributo un valor repetido. TODOS los atributos que son CLAVE cumplen esta restricción. Aunque es posible que otros atributos que no siendo clave la cumplan.
- Restricción de verificación (CHECK): Esta restricción permite comprobar si un valor de un atributo es válido de acuerdo a una expresión.
- Restricción de valor NULO (NULL o NOT NULL): Un atributo puede ser obligatorio si no admite un valor nulo o null, es decir, el valor no tiene información o se desconoce. Si admite como valor a NULO o NULL, entonces el valor es opcional.
- Disparadores o triggers: Son procedimientos que se ejecutan para hacer una tarea concreta en el momento de insertar, modificar o eliminar información de una tabla.
Integridad de entidad
Una de las principales ventajas que ofrece el Modelo
Relacional es la utilización de las reglas de integridad, las cuales son
restricciones que se aplican a los datos en función de los conceptos de las
bases de datos relaciones y de las organizaciones en las que se implementan. Además,
aseguran que en la base de datos no se almacenen valores inválidos para la
organización que implementa un sistema informático que utiliza como base el
modelo relacional para almacenamiento de sus datos.
Integridad de las entidades
Se basa en las claves primarias de cada relación y de todas
las relaciones en el modelo relacional. Exige que la clave primaria no asuma,
NUNCA, un valor desconocido. Debido a que la clave primaria NO puede ser
desconocida.
Integridad referencial
Esta regla se define sobre la base de las claves foráneas y
restringe las relaciones entre relaciones. Se da cuando una tabla tiene una
referencia a un valor de otra tabla. En este caso la restricción exige que
exista el valor referenciado en la otra tabla. Por ejemplo no se puede colocar
o asignar la calificación de la asignatura de Fundamentos de Base de Datos un
alumno que no exista.
Integridad de dominio
Esta restricción exige que el valor que puede tomar un campo
esté dentro del dominio definido. Por ejemplo, si se establece que un campo NC
(número de control) pertenece al dominio de los números enteros, no es posible
insertar un NC con letra, puesto que la regla indica solo valores enteros.

El modelo de datos relacional es hoy el modelo de mayor uso
y difusión en los distintos tipos de organizaciones, aunque con importantes
cambios y adecuaciones realizados a través del tiempo.
El objetivo principal del modelo relacional es proteger al
usuario de la obligación de conocer la estructura física de los datos, es
decir, con la representación de ellos a nivel físico dentro de la base de
datos. Esto permite generar un diseño que sea capaz de implementarse en diferentes
gestores de bases de datos.
Sus características son:
1.- La relación es el elemento fundamental del modelo, las
cuales se pueden manipular con el álgebra relacional.
2.- Es independiente de la forma en que se almacenan los
datos y su representación, por lo que se puede implementar en cualquier SGBD.
3.- Esta fundamentado en una base matemática, por lo que al
hacer uso de operaciones de conjuntos lo hace eficaz.
En una base de datos relacional, los datos son recolectados
mediante relaciones, y estas a su vez son generalmente representadas mediante
tablas.
Se define una relación como un conjunto de atributos, cada
uno de los cuales pertenece a un dominio, y que posee un nombre que identifica
la relación. Se representa gráficamente mediante una tabla con columnas (ATRIBUTOS)
y filas (TUPLAS). El conjunto de TUPLAS de una relación representa el CUERPO de
la relación y el conjunto de atributos y el nombre representan el ESQUEMA. Las
filas o tuplas contienen datos reales.
CONCEPTOS BÁSICOS:
Atributo (Columna): Características que describen a una
entidad o relación.
Dominio: Conjunto de valores permitidos para un atributo,
por ejemplo, cadenas de caracteres, números para la edad, valores como SI o NO,
Masculino-Femenino, etc.
Cabecera: Conjunto de atributos de una relación conforma la
cabecera de la relación.
Dato: Es la unidad mínima de información e indivisible,
ejemplo el valor que representa la edad de una persona.
Grado: Es el número de columnas que conforman la relación,
este valor no cambia por lo que se dice es estático, solo puede ser modificado por necesidad de la organización.
Cardinalidad: Es el número de tuplas o filas de una
relación, este valor cambia de manera constante por lo que es dinámico, y que
depende del agregado o eliminación de relaciones o tuplas.
CLAVE
Una clave es un conjunto de atributos que identifican de
forma única una ocurrencia de entidad. En este caso las claves pueden ser simples
(atómicas) o compuestas. Existen varios tipos de clave, entre estas
encontramos:
Superclave: Identifican a una entidad, pueden ser no
mínimas, como el número-seguridad-social, CURP, o bien, compuestas como
RFC+Número-seguridad-social.
Clave Candidata: Es la mínima superclave, por ejemplo puede
ser solo el RFC, CURP, entre otros.
Clave Primaria (PK): Es la clave candidata elegida por el
diseñador como clave definitiva para una entidad o relación.
Clave foránea (FK): Es un atributo de una entidad, que es la
CLAVE en otra entidad.